

 如果结果不匹配,请
如果结果不匹配,请 
 更多“过拟合是指为追求样本集中样本的正确分类性导致分类器泛化能力降…”相关的问题
更多“过拟合是指为追求样本集中样本的正确分类性导致分类器泛化能力降…”相关的问题
A.样本单位比较集中,进行调查对比较方便
B.样本单位的代表性较好
C.调查费用较高
D.要求各群体之间具有差异性,每一群体内部的元素具有相同性
A.样本单位比较集中,进行调查时比较方便
B.样本单位的代表性较好
C.调查费用较高
D.分群抽样要求各群体之间具有差异性,每一群体内部的元素具有相同性
A.样本选择与预处理->区域选择->特征获取->分类器分类
B.样本选择与预处理->特征获取->分类器分类->区域选择
C.区域选择->样本选择与预处理->分类器分类->特征获取
D.区域选择->样本选择与预处理->特征获取->分类分类
利用NYSE.RAW中的数据。
(i)估计教材方程(12.47)中的模型并求OLS残差平方。求u2t在整个样本中的平均值、最小值和最大值。
(ii)利用OLS残差平方估计如下的异方差性模型
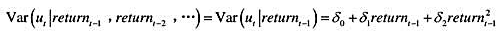
报告估计系数、标准误、R²和调整R²。
(ii)将条件方差描述成滞后return-1的函数。方差在return_,取何值时最小?这个方差是多少?
(iii)为了预测动态方差,第(ii)部分的模型得到了负的方差估计值吗?
(v)第(ii)部分中的模型拟合效果比教材例12.9中的ARCH(1)模型更好还是更差?请解释。
(vi)在教材方程(12.51)的ARCH(1)回归中添加二阶滞后ut-22。这个滞后看起来重要吗?这个ARCH(2)模型比第(ii)部分中的模型拟合得更好吗?
利用BARIUM.RAW中的数据。
(i)用前119次观测(即不包含1988年的最后12个月观测),估计线性趋势模型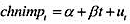 。这个回归的标准误是什么?
。这个回归的标准误是什么?
(ii)同样用除了最后12个月以外的所有数据,估计chnimp的一个AR(1)模型。把这个回归的标准误与第(i)部分中的标准误相比较。哪一个模型提供了更好的样本内拟合?
(iii)用第(i)和第(ii)部分中的模型计算1988年12个月的提前一期预测误差。(每个方法都应该得到12个预测误差。)计算并比较这两种方法的RMSE和MAE。就样本外提前一期预测而言,哪种方法效果更好?
(iv)在第(i)部分的回归中添加月度虚拟变量。它们是联合显著的吗?(当我们检验联合显著性时,不必担心误差中轻度的序列相关。)
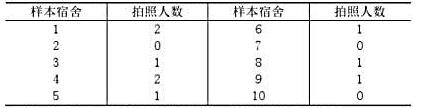
试估计拍摄过个人艺术照的女生比例,并给出估计的标准差。
















