 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
在一个具有K个方程的模型系统中,任何一个方程被识别的充分必须条件是:所有不包含在这个方程中变量的参数矩阵的秩等于(),这称为识别的()。
在一个具有K个方程的模型系统中,任何一个方程被识别的充分必须条件是:所有不包含在这个方程中变量的参数矩阵的秩等于(),这称为识别的()。
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
 更多“在一个具有K个方程的模型系统中,任何一个方程被识别的充分必须…”相关的问题
更多“在一个具有K个方程的模型系统中,任何一个方程被识别的充分必须…”相关的问题
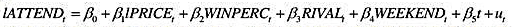
其中,PRICEl表示门票价格(可能以真实价格度量,比如通过地区消费者价格指数进行平减),WINPERCl表示球队当前获胜的概率,RIVALl表示一个标志着比赛是否势均力敌的虚拟变量,而WEEKEND表示一个标志着球赛是否在周末进行的虚拟变量。I表示自然对数,所以这个需求函数具有常价格弹性。
(i)为什么在这个方程中有一个时间趋势是个好想法?
(ii)门票供给由体育馆的容量所固定;假定这个供给10年不变。这意味着供给的数量不随价格而变化。这意味着价格在这个需求方程中必然是外生变量吗?(提示:回答是否定的。)
(iii)假设门票的名义价格缓慢变化(如在每个赛季之初)。体育委员会部分基于上赛季的平均售票和该队上赛季的胜率来选择价格。在什么样的条件下,上个赛季的胜率(SEASt-1)是IPRICEt一个有效的工具变量?
(iv)在方程中包括男子篮球比赛的真实价格(的对数)看起来合理吗?请解释。经济理论预测其系数的符号是什么样的?你能想到另外一个与男子篮球相关而又属于女子观众方程的变量吗?
(v)如果你担心某些序列(特别是IATTEND和IPRICE)有单位根,你如何改变所估计的方程?
(vi)如果某些比赛的门票售空,这会导致估计需求方程出现什么问题?(提示:如果门票售空,你一定观察到真实需求了吗?)
a)图7-21中的边能剖分为两条路(边不相重),试给出这样的剖分。
b)设G是一个具有k个奇数度结点(k>0)的连通图,证明在G中的边能剖分为k/2条路(边不相重)。
c)设G是一个具有k个奇数度结点的图,问最少加几条边到G中,而使所得的图有一条欧拉回路,说明对于图7-21如何能做到这一点。
d)在c)中如果只允许加平行于G中已存在的边,问最少加几条边到G中,使所得的图中有一条欧拉回路,这事总能做到吗?叙述能做到这事的充分必要条件。
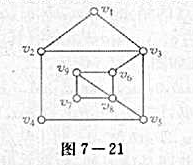
利用WAGEPAN.RAW中的数据。
(i)考虑非观测效应模型
(ii)用FD估计第(i)部分中的方程,并检验不同时期的教育回报没有变化的原假设。
(iii)利用一个足够稳健的检验,也就是容许FD误差Δuir中存在任何形式的异方差和序列相关的检验,检验第(ii)部分中的假设。你的结论有变化吗?
(iv)现在,容许是否加入工会的差别(与受教育水平一起)在不同时期有所变化,用FD估计这个方程。1980年加入工会与不加入工会的估计工资差别是多少?1987年呢?这个差别在统计上显著吗?
(v)检验工会关系差别在不同时期没有发生变化的原假设,并根据你对第(iv)部分的回答讨论你的结论。
试设计一个算法,利用T公司提供的m个补丁程序,将原软件修复成一个没有错误的软件,并使修复后的软件耗时最少.
算法设计:对于给定的n个错误和m个补丁程序,找到总耗时最少的软件修复方案.
数据输入:由文件input.txt提供输入数据.文件第1行有2个正整数n和m,n表示错误总数,m表示补丁总数(1≤n≤20,1≤m≤100).接下来m行给出了m个补丁的信息.每行包括一个正整数,表示运行补丁程序i所需时间以及2个长度为n的字符串,中间用个空格符隔开.在第1个字符串中,如果第k个字符bk为“+”,则表示第k个错误属于B1[i],若为“-”,则表示第k个错误属于B2[i],若为“0”,则第k个错误既不属于B1[i]也不属于B2[i],即软件中是否包含第k个错误并不影响补丁i的可用性.在第2个字符串中,如果第k个字符bk为“+”,则表示第k个错误属于F1[i],若为“-”,则表示第k个错误属于F2[i],若为“0”,则第k个错误既不属于F1[i]也不属于F2[i],即软件中是否包含第k个错误不会因使用补丁i而改变.
结果输出:将总耗时数输出到文件output.txt.如果问题无解,则输出0.

用到SMOKE.RAW中的数据。
(i)估计抽烟影响年收入(可能通过因病损失的工作日或生产力效应)的一个模型是
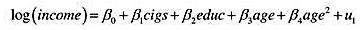
其中,cigs表示平均每天抽烟的数量。你如何解释民?
(ii)为了反映香烟消费可能与收入同时决定,一个香烟需求方程是
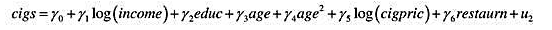
其中,cigpric表示每包香烟的价格(美分),而restaurn表示一个二值变量,并在这个人所定居的州有餐馆抽烟限制时等于1。假定这些变量对个人而言都是外生的,那么你预期y5和y6具有什么样的符号?
(iii)在什么样的条件下第(i)部分的收入方程可识别?
(iv)用OLS估计收入方程并讨论p,的估计值。
(v)估计cigs的约简型。(记住这就要求将cigs对所有外生变量回归。)log(cigprc)和restaurn在约简型中显著吗?
(vi)现在用2SLS估计收入方程。讨论的估计值与OLS估计值的比较。
(vii)你认为香烟价格和餐馆抽烟限制在收入方程中是外生的吗?
在化工产业的企业总体中,令rd表示年研发支出,sales表示年销售额(都以百万美元计)。
(i)写一个模型(不是估计方程),其中rd和sales之间的弹性为常数。哪一个参数代表弹性?
(ii)再用RDCHEM.RAW中的数据估计模型。用通常的形式写出估计方程。rd关于sales的弹性估计值是多少?用文字解释这个弹性的含义。
互联网是一张有向图,每一个网页是图的一个顶点,网页间的每一个超链接是图的一个边,邻接矩阵B=(b)w如果从网页i到网页j有超链接,则by=1,否则为0。
记矩阵B的列和及行和分别是 它们分别给出了页面j的链人链接数目和页面i的链出链接数目。假如在上网时浏览页面并选择下一个页面的过程,与过去浏览过哪些页面无关,而仅依赖于当前所在的页面。那么这一-选择过程可以认为是一一个有限状态、离散时间的随机过程,其状态转移规律用Markov链描述。定义矩阵A=(ay)wxn为
它们分别给出了页面j的链人链接数目和页面i的链出链接数目。假如在上网时浏览页面并选择下一个页面的过程,与过去浏览过哪些页面无关,而仅依赖于当前所在的页面。那么这一-选择过程可以认为是一一个有限状态、离散时间的随机过程,其状态转移规律用Markov链描述。定义矩阵A=(ay)wxn为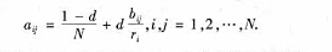 式中:d是模型参数,通常取d=0.85;A是Markov链的转移概率矩阵;ay表示从页面i转移到页而j的概率。根据Markov链的基本性质,对于正则Markov链存在平稳分布x=
式中:d是模型参数,通常取d=0.85;A是Markov链的转移概率矩阵;ay表示从页面i转移到页而j的概率。根据Markov链的基本性质,对于正则Markov链存在平稳分布x= 式中:x为在极限状态(转移次数趋于无限)下各网页被访问的概率分布,Google将它定义为各网页的PageRank值。假设x已经得到,则它按分量满足方程
式中:x为在极限状态(转移次数趋于无限)下各网页被访问的概率分布,Google将它定义为各网页的PageRank值。假设x已经得到,则它按分量满足方程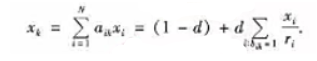 网页i的PageRank值是划,它链出的页面有τ个,于是页面i将它的PageRank值分成r份,分别“投票"给它链出的网页。x为网页k的PageRank值,即网络上所有页面“投票给网页k的最终值。根据Markov链的基本性质还可以得到,平稳分布(即PageRank值)是转移概率矩阵A的转置矩阵AT的最大特征值(=1)所对应的归一化特征向量。
网页i的PageRank值是划,它链出的页面有τ个,于是页面i将它的PageRank值分成r份,分别“投票"给它链出的网页。x为网页k的PageRank值,即网络上所有页面“投票给网页k的最终值。根据Markov链的基本性质还可以得到,平稳分布(即PageRank值)是转移概率矩阵A的转置矩阵AT的最大特征值(=1)所对应的归一化特征向量。
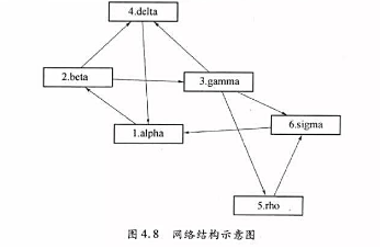
已知一个N=6的网络如图4.8所示,求它的PageRank取值。
下列关于回归模型的说法,正确的是()。
A.一元线性回归模型是用于分析一个自变量X与一个因变量Y之间线性关系的数学方程
B.判定系数r2表明指标变量之间的依存程度,r2越大,表明依存度越大
C.在一元线性回归分析中,b的t检验和模型整体的F检验二者取其一即可
D.在多元回归分析中,b的t检验和模型整体的F检验是不等价的
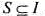 ,使得在X轴上的任何一点p,S中与直线x=p相交的开线段个数不超过k,且
,使得在X轴上的任何一点p,S中与直线x=p相交的开线段个数不超过k,且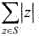 达到最大.这样的集合S称为开线段集合的最长k可重线段集,
达到最大.这样的集合S称为开线段集合的最长k可重线段集,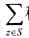 称为最长k可重线段集的长度.
称为最长k可重线段集的长度.对于任何开线段z,设其端点坐标为(x0,y0)和(x1,y1),则开线段z的长度定义为
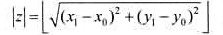
算法设计:对于给定的开线段集合I和正整数k.计算开线段集合I的最长k可重线段集的长度.
数据输入:由文件input.txt提供输入数据.文件的第1行有2个正整数n和k,分别表示开线段的个数和开线段的可重叠数.接下来的n行,每行有4个整数,表示开线段的2个端点坐标.
结果输出:将计算的最长k可重线段集的长度输出到文件output.txt.

(i)在模型GPA=β0+β1study+β1sleep+β1work+β1leisure+u中,保持sleep,work和leisure不变而改变study是否有意义?
(ii)解释为什么这个模型违背了假定MLR.3。
(iii)你如何才能将这个模型重新表述,使得它的参数具有一个有用的解释,而又不违背假定MLR.3。

















