题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
K-means++算法选择初始seeds的基本思想就是:初始的聚类中心之间的相互距离要尽可能的远。那么算法流程为()。1.从输入的数据点集合中随机选择一个点作为第一个聚类中心2.对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)3.选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大4.重复2和3直到k个聚类中心被选出来5.利用这k个初始的聚类中心来运行标准的k-means算法。
A.2.5.4.3.1
B.1.5.4.2.3
C.1.2.3.4.5
D.4.3.2.1.5
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“K-means++算法选择初始seeds的基本思想就是:初始…”相关的问题
更多“K-means++算法选择初始seeds的基本思想就是:初始…”相关的问题
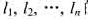 的n个程序放在磁带T1和T2上,并且希望按照使最大检索时间取最小值的方式存放,即如果存放在T1和T2上的程序集合分别是A和B,则希中所选择的A和B使得
的n个程序放在磁带T1和T2上,并且希望按照使最大检索时间取最小值的方式存放,即如果存放在T1和T2上的程序集合分别是A和B,则希中所选择的A和B使得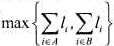 取最小值.
取最小值.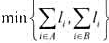 则将当前正在考虑的那个程序分配给A,否则分配给B.证明无论是按
则将当前正在考虑的那个程序分配给A,否则分配给B.证明无论是按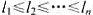 还是按
还是按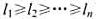 的次序来考虑程序的,这种方法都不能产生最优解.应当采用什么策略?写出一个完整的算法并证明其正确性.
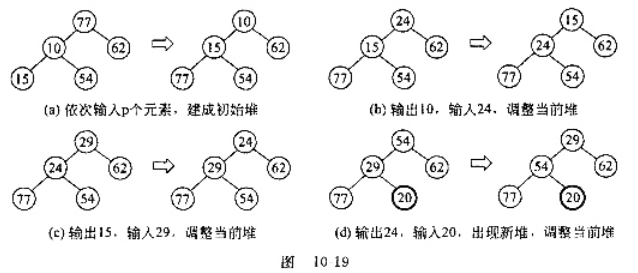
的次序来考虑程序的,这种方法都不能产生最优解.应当采用什么策略?写出一个完整的算法并证明其正确性.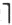 ,应着手调整新堆;如果新堆中已有p个记录,表示当前堆已输出完毕,当前的初始归并段结束、应开始创建下一个初始归并段,因此必须另为新堆选择一个磁盘文件作为输出文件。
,应着手调整新堆;如果新堆中已有p个记录,表示当前堆已输出完毕,当前的初始归并段结束、应开始创建下一个初始归并段,因此必须另为新堆选择一个磁盘文件作为输出文件。