 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
数据集SMOKE.RAW包含美国成人个人随机样本在抽烟行为和其他变量方面的信息。变量cigs为(平均)每
数据集SMOKE.RAW包含美国成人个人随机样本在抽烟行为和其他变量方面的信息。变量cigs为(平均)每天抽烟的数量。你是否认为在美国这个总体中,cigs具有正态分布?试做解释。
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
数据集SMOKE.RAW包含美国成人个人随机样本在抽烟行为和其他变量方面的信息。变量cigs为(平均)每天抽烟的数量。你是否认为在美国这个总体中,cigs具有正态分布?试做解释。
如果结果不匹配,请 联系老师 获取答案
 更多“数据集SMOKE.RAW包含美国成人个人随机样本在抽烟行为和…”相关的问题
更多“数据集SMOKE.RAW包含美国成人个人随机样本在抽烟行为和…”相关的问题
用到SMOKE.RAW中的数据。
(i)估计抽烟影响年收入(可能通过因病损失的工作日或生产力效应)的一个模型是
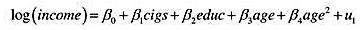
其中,cigs表示平均每天抽烟的数量。你如何解释民?
(ii)为了反映香烟消费可能与收入同时决定,一个香烟需求方程是
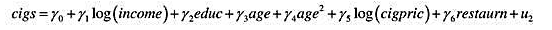
其中,cigpric表示每包香烟的价格(美分),而restaurn表示一个二值变量,并在这个人所定居的州有餐馆抽烟限制时等于1。假定这些变量对个人而言都是外生的,那么你预期y5和y6具有什么样的符号?
(iii)在什么样的条件下第(i)部分的收入方程可识别?
(iv)用OLS估计收入方程并讨论p,的估计值。
(v)估计cigs的约简型。(记住这就要求将cigs对所有外生变量回归。)log(cigprc)和restaurn在约简型中显著吗?
(vi)现在用2SLS估计收入方程。讨论的估计值与OLS估计值的比较。
(vii)你认为香烟价格和餐馆抽烟限制在收入方程中是外生的吗?
数据集401KSUBS.RAW包含了净金融财富(nenfa)、被调查者年龄(age)、家庭年收入(inc)、家庭规模(fsize)方面的信息,以及参与美国个人的特定养老金计划方面的信息。财富和收入变量都以千美元为单位记录。对于这里的问题,只使用无子女已婚者数据(marr=1,fsize=2)。
(i)数据集中有多少无子女已婚夫妇?
(ii)利用OLS估计模型
nettfa=β0+β1inc+β2age+u;
并以常用格式报告结果。解释斜率系数。斜率估计值有何惊人之处吗?
(iii)第(ii)部分的回归截距有重要意义吗?请解释。
(iv)在1%的显著性水平上,针对H0:β2>1检验H0: β2=1,求出p值。你能拒绝H0吗?
(V)如果你做一个nettfa对inc的简单回归,inc的斜率估计值与第(ii)部分的估计值有很大不同吗?为什么?
薪水信息和职业统计。
(i)估计一个将每场得分(points)与加入联盟年数(exper)、年龄(age)、大学期间打球年数(coll)相联系的模型。包含一个exper的二次项,其他变量都应该以水平值形式加入模型。按照通常的格式报告结果。
(ii)保持大学打球年数和年龄不变,从加入联盟的第几个年份开始,在NBA打球的经历实际上将降低每场得分?这讲得通吗?
(iii)你为什么认为coll具有负系数,而且统计显著?(提示:NBA运动员在读完大学之前被选拔出,甚至直接从高中选出。)
(iv)有必要在方程中增加age的二次项吗?一旦控制了exper和coll之后,这对年龄效应意味着什么?
(v)现在将log(wage)对points,exper,exper2,age和coll回归。以通常的格式报告结论。
(vi)在第(v)部分的回归中检验age和coll是否联合显著。一旦控制了生产力和资历,这对考察年龄和受教育程度是否对工资具有单独影响这个问题有何含义?
A.地理信息系统
B.排水管网管理信息系统
C.管道信息系统
D.污水信息系统
A.MapRuduce分布式计算模型,用于处理大数据量的计算,包含map和reduce两个阶段
B.Map阶段对数据集上的独立元素进行指定操作,生成键值对形式的中间结果
C.reduce阶段对中间结果中的键和所有的值进行规约,以得到最终的结果
D.Map和Ruduce两个操作还有进一步的细分,分解后的原操作可以进一步进行灵活的组合
(i)令yt代表真实个人可支配收入。用直至1989年的数据估计如下模型:
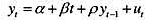
并用通常的格式报告结果。
(ii)用第(i)部分估计的方程预测1990年的y。预测误差是多少?
(iii)用第(i)部分估计的参数,计算20世纪90年代提前一期预测值的MAE。
(iv)把yt-1从方程中去掉后,计算相同时期内的MAE。在模型中包含yt-1更好些吗?

















