 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
在例7.12中,我们估计了一个线性概率模型以说明一个年轻人在1986年是否被拘捕:(i)用OLS估计此模
在例7.12中,我们估计了一个线性概率模型以说明一个年轻人在1986年是否被拘捕:(i)用OLS估计此模
在例7.12中,我们估计了一个线性概率模型以说明一个年轻人在1986年是否被拘捕:
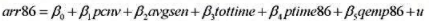
(i)用OLS估计此模型, 并验证其全部估计值都严格地介于0和1之间。最大和最小的估计值各是多少?
(ii)像8.5节所讨论的那样,用加权最小二乘法估计这个方程。
(iii)用WLS估计值决定avgsen和tottie在5%的显著性水平上是否联合显著。
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“在例7.12中,我们估计了一个线性概率模型以说明一个年轻人在…”相关的问题
更多“在例7.12中,我们估计了一个线性概率模型以说明一个年轻人在…”相关的问题

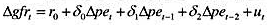
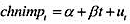 。这个回归的标准误是什么?
。这个回归的标准误是什么?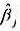 中的估计误差,那么y0的一个95%预测区间就是
中的估计误差,那么y0的一个95%预测区间就是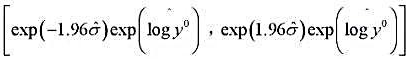
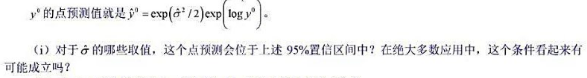 。
。















