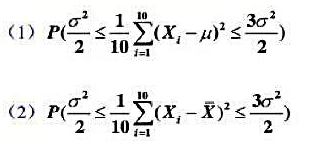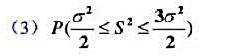如果结果不匹配,请
如果结果不匹配,请 
 更多“25个雇员的随机样本的平均周薪为130元,试问此样本是否取自…”相关的问题
更多“25个雇员的随机样本的平均周薪为130元,试问此样本是否取自…”相关的问题
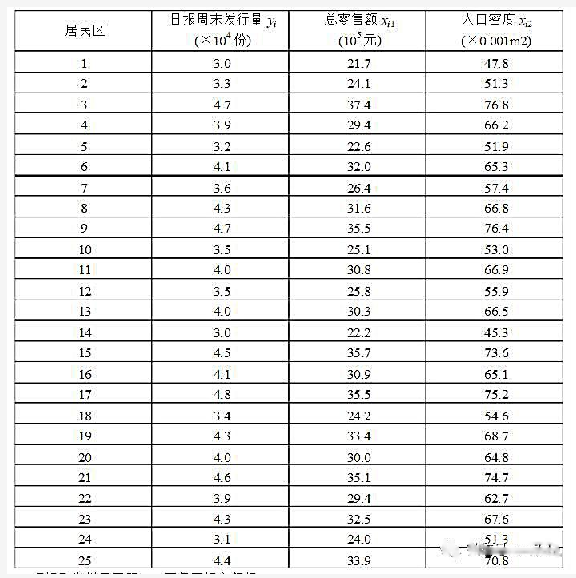
数据集SMOKE.RAW包含美国成人个人随机样本在抽烟行为和其他变量方面的信息。变量cigs为(平均)每天抽烟的数量。你是否认为在美国这个总体中,cigs具有正态分布?试做解释。
本题利用JTRAIN.RAW来判断工作培训资助对每位雇员的平均培训小时数的影响。三年的基本模型为
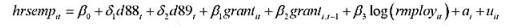
(i)利用一阶差分估计这个方程。估计中使用了多少个企业?如果每个企业都有这三个时期所有变量的数据(特别是hrsemp的数据) , 那么, 总共将使用多少观测?
(ii)解释grant的系数并评论其显著性。
(iii)grant,是不显著的, 这让你感到意外吗?请加以解释。
(iv)平均而言,越大的企业对其员工的培训是越多还是越少呢?在培训上的差异有多大呢?
利用JTRAIN.RAW,以确定工作培训津贴对每个雇员工作培训小时数的影响。三年的基本模型是:

(i)用固定效应法估计方程。在此估计中利用了多少个企业?如果每个企业都有这三年的所有变量数据(特别是hrsemp的数据),总观测个数会是多少?
(ii)解释grant的系数并评论它的显著性。
(iii)grant-1不显著有什么惊人之处吗?请解释。
(iv)平均地说,更大的企业为其职工提供了更多还是更少的培训?差别有多大?(比方说,职工多10%的企业,培训的平均小时数增多或减少了多少?)
A.67500
B.20250
C.9300
D.10200
A.借记“管理费用”科目1 130元
B.借记“材料采购”科目1 130元
C.贷记“其他货币资金”科目1 130元
D.贷记“银行存款”科目1 130元
考虑一个雇员水平的模型
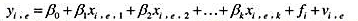
其中无法观测变量f是在一个给定的企业i内,对每个雇员的“企业效应”。误差项vi,e是企业i中雇员e所独具的。诸如方程(8.28)中的综合误差就是ui,e=fi+ui,e.

(iv)讨论第(ii)部分对于利用企业层次的平均数据进行WLS估计的意义,其中第i次观测所用的权数就是通常的企业规模。
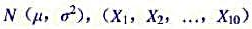 为来自总体X的简单随机样本,试求下列概率:
为来自总体X的简单随机样本,试求下列概率: