 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
通过训练有标记的数据,形成模型后再让计算机对新的数据进行分类,属于人工智能中的__________。
A.无监督学习
B.有监督学习
C.半监督学习
D.强化学习
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.无监督学习
B.有监督学习
C.半监督学习
D.强化学习
如果结果不匹配,请 联系老师 获取答案
 更多“通过训练有标记的数据,形成模型后再让计算机对新的数据进行分类…”相关的问题
更多“通过训练有标记的数据,形成模型后再让计算机对新的数据进行分类…”相关的问题
A.单叶重数据一般定点采集,从第一次采收时开始采集数据
B.每个档次的烟田选择1-2个点,每个点确定50-100株
C.从下部叶到上部叶依次进行标记,并带标记采收调制
D.统计烤(晾)后分部位的总叶数、总重量,烤(晾)全部结束后汇总统计结果,计算平均单叶重,并按品种、地块档次分别记录。
(i)令yt代表真实个人可支配收入。用直至1989年的数据估计如下模型:
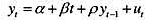
并用通常的格式报告结果。
(ii)用第(i)部分估计的方程预测1990年的y。预测误差是多少?
(iii)用第(i)部分估计的参数,计算20世纪90年代提前一期预测值的MAE。
(iv)把yt-1从方程中去掉后,计算相同时期内的MAE。在模型中包含yt-1更好些吗?
A.通过IFC或StructureModelCenter数据计算模型
B.开展抗震、抗风、抗火等结构性能设计
C.结构计算结果存储在BIM模型或者信息管理平台中,便于后续应用
D.基于BIM技术对建筑能耗进行计算、评估。进而开展能耗性能优化
E.基于BIM技术对其进行场地分析
利用CEOSAL2.RAW中的数据估计模型
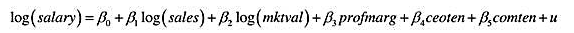
所得到的R²为R²=0.353(n=177)。若添加ceoten²和comten²后,R²=0.375。此模型中是否有函数形式误设的证据?
列。
(i)用OLS估计模型 并检验误差中的AR(1)序列相关。假定回归元是严格外生的。误差中有正或负的序列相关吗?
并检验误差中的AR(1)序列相关。假定回归元是严格外生的。误差中有正或负的序列相关吗?
(ii)用迭代的普莱斯一温斯顿检验方法估计(i)中的模型。gmwage的系数与用OLS方法相比有什么区别?
(iii)在第(ii)部分的方程中增加gmwage的1~12阶滞后项并用迭代的普莱斯-温斯顿方法估计该模型,检验这12个滞后项是否为联合显著的。
(iv)我们回到在第(i)部分估计出的静态模型,用6阶滞后项计算尼威-韦斯特标准误。用尼威一韦斯特方法计算的标准误和普通的OLS标准误相比有什么区别?
(v)在静态模型中增加gwage的1~12阶滞后项,并用6阶滞后项的尼威-韦斯特检验方法检查12阶滞后项的联合显著性。你的结论和第(ii)部分相比有区别吗?
在第4章习题11中, 利用CEOS AL 2.RAW中的数据估计模型
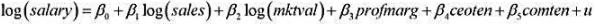
所得到的R2为R2=0.353(n=177) 。若添加ceo ten2和cem ten2后, R2=0.375。此模型中是否有函数形式误设的证据?
A.计算机上的数据安全不重要
B. 计算机病毒、机器故障、突然断电等情况都可能造成计算机上的重要资料、劳动成果发生丢失或毁损。最可靠的办法就是做好重要数据的备份
C. 计算机病毒、机器故障、突然断电等情况不可能造成计算机上的重要资料、劳动成果发生丢失或毁损
D. 文件备份无需定期进行并做好标记,日后很容易查找
A.①②④③
B.②①③④
C.①②③④
D.②①④③
A.读取模型优化器的中间文件进行处理
B.直接读入新数据到中间文件进行推理计算
C.可以使用多个硬件共同承担推理计算任务,提高效率
D.利用训练好的模型,支持用户做高效的机器视觉任务,支持边缘计算的时间要求

















