

 如果结果不匹配,请
如果结果不匹配,请 
 更多“在数据安全领域常用的P2DR模型中,P、D和R代表的是()。”相关的问题
更多“在数据安全领域常用的P2DR模型中,P、D和R代表的是()。”相关的问题
利用DISCRIM.RAW中的数据回答本题。(也可参见第3章计算机练习C8。)
(i)利用OLS估计模型
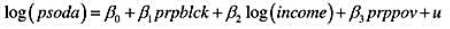
以常用形式报告结果。在5%的显著性水平上,相对一个双侧备择假设,β统计显著异于零吗?在1%的显著性水平上呢?
(ii)log(income)和prppov的相关系数是多少?每个变量都是统计显著的吗?报告双侧P值。
(iii)在第(i)部分的回归中增加变量log(hseval)。解释其系数并报告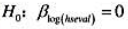 的双侧p值。
的双侧p值。
(iv)在第(ii)部分的回归中,log(income)和prppov的个别统计显著性有何变化?这些变量联合显著吗?(计算一个p值。)你如何解释你的答案?
(v)给定前面的回归结果,在确定一个地区的种族构成是否影响当地快餐价格时,你会报告哪一个结果才最为可靠?
A.实验数据的个数,权重残差平方和,所设模型参数的个数
B.所设模型参数的个数,残差平方和,实验数据的个数
C.所设模型参数的个数,权重残差平方和,实验数据的个数
D.实验数据的个数,残差平方和,所设模型参数的个数
数据集401KSUBS.RAW包含了净金融财富(nenfa)、被调查者年龄(age)、家庭年收入(inc)、家庭规模(fsize)方面的信息,以及参与美国个人的特定养老金计划方面的信息。财富和收入变量都以千美元为单位记录。对于这里的问题,只使用无子女已婚者数据(marr=1,fsize=2)。
(i)数据集中有多少无子女已婚夫妇?
(ii)利用OLS估计模型
nettfa=β0+β1inc+β2age+u;
并以常用格式报告结果。解释斜率系数。斜率估计值有何惊人之处吗?
(iii)第(ii)部分的回归截距有重要意义吗?请解释。
(iv)在1%的显著性水平上,针对H0:β2>1检验H0: β2=1,求出p值。你能拒绝H0吗?
(V)如果你做一个nettfa对inc的简单回归,inc的斜率估计值与第(ii)部分的估计值有很大不同吗?为什么?
A.信息安全研究人员更关注从实践中采用数学方法精确描述安全属性,通过安全模型来解决信息安全问题
B.信息安全也可以看成是计算机网络上的信息安全,凡涉及网络信息的可靠性、保密性、完整性、有效性、可控性和拒绝否认性的理论、技术与管理都属于信息安全的研究范畴
C.信息安全就是为防范计算机网络硬件、软件、数据偶然或蓄意破环、篡改、窃听、假冒、泄露、非法访问和保护网络系统持续有效工作的措施总和
D.信息安全是一个涉及计算机科学、网络技术等多个领域的复杂系统工程
A.关键词提取是指用人工方法提取文章关键词的方法
B.TF-IDF模型是关键词提取的经典方法
C.文本中出现次数最多的词最能代表文本的主题
D.这个问题设计数据挖掘,文本处理,信息检索等领域
















