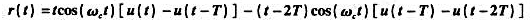如果结果不匹配,请
如果结果不匹配,请 
 更多“试证明,在大o记号的意义下a)等差级数之和与其中最大一项的平…”相关的问题
更多“试证明,在大o记号的意义下a)等差级数之和与其中最大一项的平…”相关的问题
若假定机器字长无限,移位操作只需单位时间,递归不会溢出,且rand()为理想的随机数发生器。试分析以下函数F(n),并以大o记号的形式确定其渐进复杂度的紧上界。








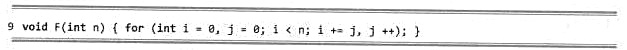
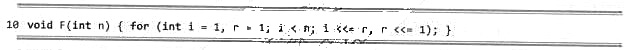
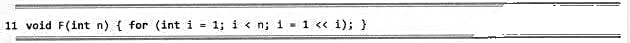

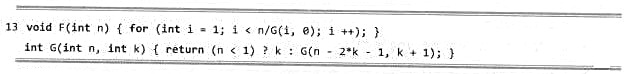
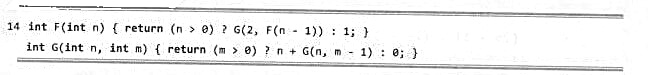
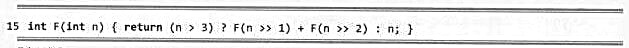

在多叉堆(d-heap)中,每个节点至多可拥有d≥3个孩子,且其优先级不低于任一孩子。
a)试证明,多叉堆decrease()接口的效率可改进至O(logdn);(当然,delMax()接口的效率因此会降至O(d-logn))。
b)试证明,若取d=e/n+2,则基于d叉堆实现的Prim算法的时间复杂度可降至O(e·logdn);
c)这种改进策略是否也适用于Dijkstra算法?
比如,若当前有: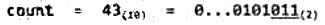
则下次递增之后将有: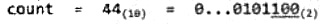
在此过程中,共有(最末尾的)三个比特发生翻转。
现在,考查对c连续的足够多次递增操作。纵观这一系列的操作,试证明:
a)每经过2^k次递增,bk恰好翻转一次;
b)对于每次递增操作,就分摊的意义而言,count只有o(1)个比特位发生翻转。
以查阅英文字典为例,单词“Data”应大致位于前1/5和1/4之间,而“Structure”则应大致位于后1/5和1/4之间。对元素的分布规律掌握得越准确,这种加速效果也就加可观。
此类方法的原理大同小异,无非是利用向量元素的分布规律,根据目标数值,通过插值估计出其大致所对应的秩,从而迅速缩小搜索范围,故称作插值查找(interpolation search)。
a)若有序向量中的元素均独立且等概率地取自某一数值区间,试证明它们应大致按线性规律分布;
b)针对此类有序向量,如何通过插值来估计待查找元素的秩?试给出具体的计算公式;
c)试证明:对于此类向量,每经一次插值和比较,待搜索区间的宽度大致以平方根的速度递减;
d)试证明:对于长度为n的此类向量,插值查找的期望运行时间为o(loglogn);
待传输标准信号表达式为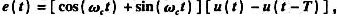 ,其中
,其中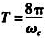 ,试证明以下结论:
,试证明以下结论:
(1)相应的匹配滤波器之冲激响应
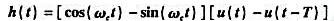
(2)在匹配条件下加入e(t),可求得输出信号