 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
利用CRIME4.RAW。 (i)使用固定效用法而不是差分法重新估计教材例13.9中关于犯罪的非观测效应模
利用CRIME4.RAW。 (i)使用固定效用法而不是差分法重新估计教材例13.9中关于犯罪的非观测效应模
利用CRIME4.RAW。
(i)使用固定效用法而不是差分法重新估计教材例13.9中关于犯罪的非观测效应模型。系数的符号和大小有什么明显变化?其统计显著性又怎样?
(ii)在数据集中添加每个工资变量的对数,再用固定效用法估计模型。添加这些变量如何影响第(i)部分有关司法变量的系数?
(iii)第(ii)部分的工资变量都带有所预期的符号吗?请解释。它们是联合显著的吗?
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“利用CRIME4.RAW。 (i)使用固定效用法而不是差分法…”相关的问题
更多“利用CRIME4.RAW。 (i)使用固定效用法而不是差分法…”相关的问题
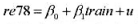 并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?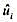 ,并将这些残差对所有的自变量进行回归。解释你为什么得到R2=0。
,并将这些残差对所有的自变量进行回归。解释你为什么得到R2=0。















